Case study
Knowledge OS
A map of research fields as evolving problems, built on 14,400 real papers.
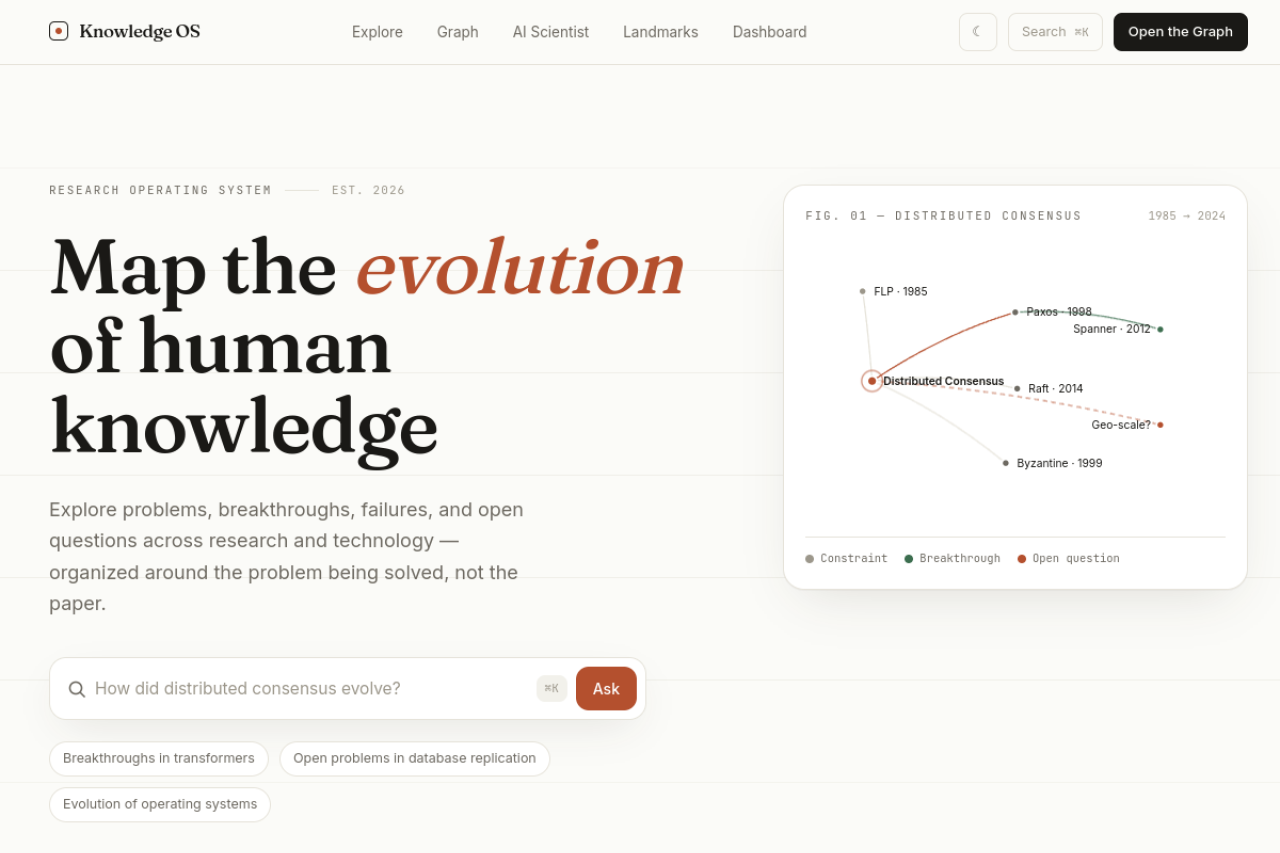
The problem
Research tools hand you papers, a long list of PDFs to wade through. They quietly skip the thing you actually want to know: how a field got here. What was tried, what flopped, what won, and what's still wide open. Knowledge OS flips that around. You browse a field as a problem, on a real map, instead of as a folder of citations.
It runs on real data: 14,400 papers and ~379k citations from OpenAlex, sorted into 36 computer-science problems and the sub-problems hiding inside them.
Architecture
The engine is layered, L0 through L6: ingest OpenAlex into SQLite, extract problems and
sub-problems with TF-IDF and K-means, compute evolution timelines and a citation "universe"
graph, then run a retrieval agent and an "AI Scientist" that points out bridge opportunities
between fields. A static export (export_static.py) turns the corpus database into
the JSON the React and Vite app reads. Nothing paid sits in the hot path.
Key decisions & trade-offs
- Static, client-side, $0 to run. The whole corpus is precomputed to JSON and served from a CDN, so there's no backend, no database, and no API keys at runtime. The trade-off: refreshing the data means re-running the pipeline, not firing a live query.
- In-browser retrieval agent instead of an LLM API. Answers are retrieved and synthesized over committed data, so there's no bill and nothing leaks to a third party. The trade-off: it's grounded retrieval, not open-ended generation. By design it would rather say less than hallucinate.
- TF-IDF and K-means for sub-problem extraction. Cheap, deterministic, and explainable, with the per-paper LLM path built but switched off by default. The trade-off: clustering is coarser than LLM-grade extraction, which is on the roadmap.
The hardest part
OpenAlex is real-world data, which means the corpus is gloriously messy: odd titles, citation counts that split or double, sparse and duplicated edges. Feeding that straight into TF-IDF and K-means produced "problems" that were really just noise, clusters that didn't map to anything a person would recognise as a field.
Getting it to read cleanly took two passes: normalising the citation graph before clustering, deduping edges and reconciling the split counts so the signal wasn't drowned out, and then tuning the feature extraction until the clusters lined up with real, nameable problems. The guiding rule was to surface the mess honestly rather than paper over it, so the occasional odd title stays visible instead of hiding behind a confident lie.
Outcome
- Live at evolve-snowy.vercel.app with 14,400 papers, ~379k citations, and 36 CS problems.
- Runs at $0 on static hosting, scales through a CDN, and ships with a test suite (
tests/test_knowledge_os.py). - Features: problem-first navigation, evolution timelines, a ⌘K research agent, a knowledge graph, and an "AI Scientist" that finds bridge opportunities across fields.
What I'd do next
From the roadmap: LLM-grade problem extraction across the full corpus, scaling toward 500k papers, and pushing past computer science. The engine is domain-agnostic, so widening it is basically one ingest filter away.