Essay · June 2026
Stop searching papers.
Start navigating problems.
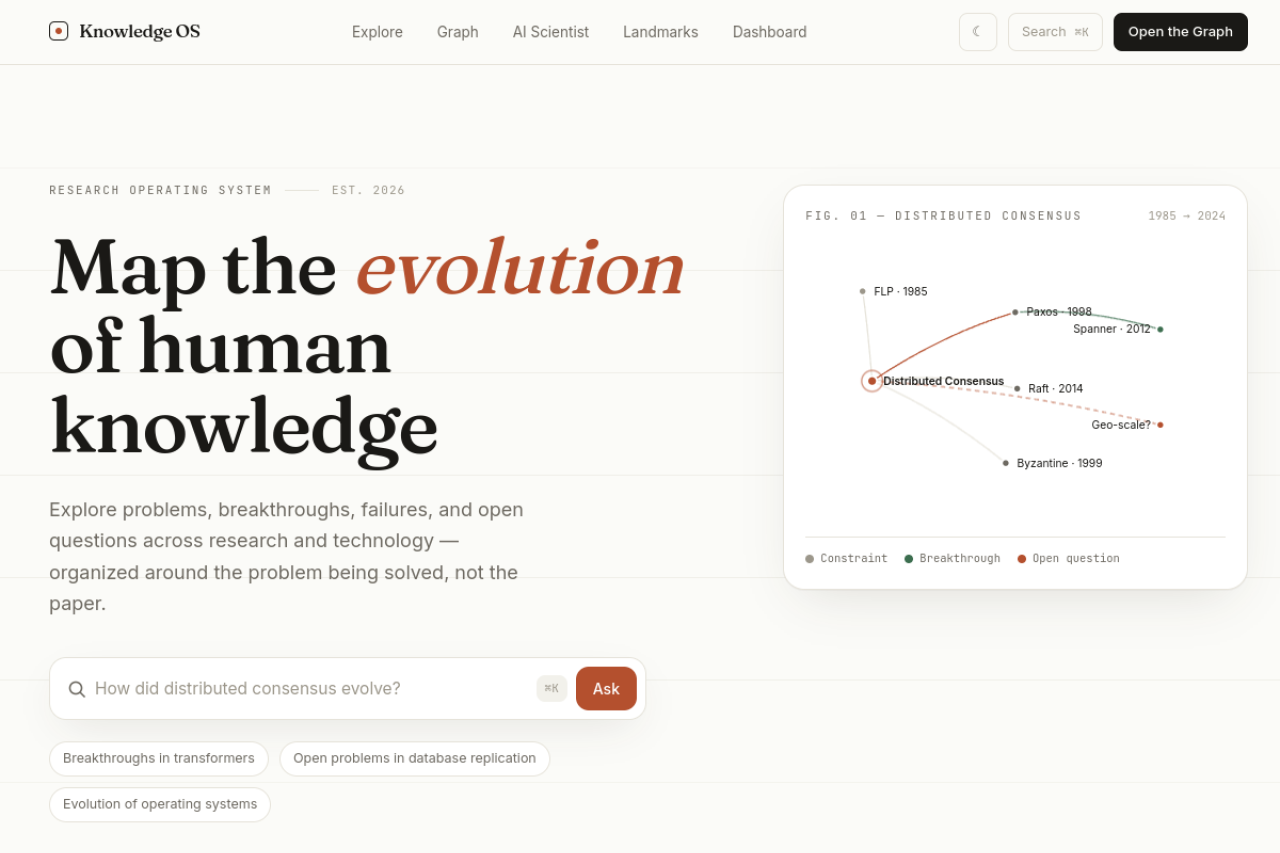
A while back I wanted to know how distributed consensus actually got solved. Not one paper. The whole story. Who tried what, what blew up, what stuck.
You know how that goes. Google Scholar hands you 2.3 million results with the confidence of someone who has never once been helpful. You open six tabs. Two are paywalled, one is a survey of surveys, one is a 1998 PDF scanned at a slight angle by a person who has since retired, and by the fourth tab you have forgotten what the question was. Forty minutes later I closed everything and read the Wikipedia article I had been specifically trying to avoid.
That bothered me more than it should have, because the information exists. It is just stored in the worst possible shape for a human being who is actually curious. Which, if we are being honest, is most of them.
Papers are the wrong unit
Here is the thing nobody says at the conference. We store knowledge as papers, but nobody thinks in papers. Nobody wakes up wanting to read paper number 4,812,003. You want to know how a problem moved. Distributed consensus. Protein folding. Word embeddings. The paper is just the box the idea shipped in, and we have spent decades lovingly cataloguing the boxes.
So the unit is wrong. Search engines, citation graphs, "related papers," all of it is built around the container instead of the thing inside it. It is like organising a kitchen by the shape of the packaging.
Flip it. Make the problem the primary object and hang everything off it: problem, then attempts, then evidence, then breakthroughs, then what is still open. That is the whole bet. You do not browse a library, you read a map. Here is how consensus evolved: FLP says it is impossible, here is the trick everyone used to dodge that, here is Paxos, here is the part where Raft won on readability of all things, here is what nobody has cracked yet.
I wanted to navigate that. So I built it. It is called Knowledge OS, it is live, and it is free.
The graveyard I was walking into
Quick reality check, because I am not the first person to think "GitHub for knowledge," and the idea has a body count. Microsoft Academic Graph: dead. Meta's Galactica, an AI that wrote science, got pulled after three days because it confidently invented things, which is a bold strategy for a science tool. A handful of others are alive in the way a houseplant is alive.
The hard part was never the database. SQLite can hold a few million rows in its sleep. The hard part is trust. The moment a tool tells a researcher something interpretive, "this approach failed," "this is unsolved," "these two fields should talk," and gets it wrong once, in their own subfield, they are gone forever. And they are right to leave.
So the design rule wrote itself. It is not allowed to make things up. Everything traces back to data. If it cannot ground a claim, it does not make the claim. Revolutionary, I know. Apparently telling the truth is a feature now.
This is also why the "AI Scientist" part, the bit that suggests where a field could go, refuses to detect contradictions. It will happily tell you "these two communities share a pile of authors but never cite each other, go poke at that," because that is just arithmetic on a graph. It will not tell you "Paper A refutes Paper B," because actually knowing that means reading the claims, and faking it is precisely how you end up as a cautionary tweet.
What I actually built
The boring and honest version:
- The corpus comes from OpenAlex, around 250 million papers, completely free, no key. I pulled 14,400 of them across 36 CS problems, with roughly 379k citation links and 25k authors, and put the lot in SQLite. OpenAlex is real-world data, which means I have a paper in there literally titled "Lecture Notes in Computer Science 1205" sitting on 38,000 citations. The real world is messy. I left the mess visible instead of pretending I had tamed it.
- Problems start as OpenAlex topic tags, then I run TF-IDF and k-means over each one to find the sub-problems hiding inside. No LLM. This is not a cost dodge. Per-paper LLM calls genuinely do not scale to millions of papers, but clustering does. The thing that is good enough and infinite beats the thing that is great and bankrupt. Every time.
- Timelines, the citation graph, what a problem draws on, all of it is just computed off the graph.
- You ask it things with ⌘K. "How did cryptography evolve?" "Who works on it?" It works out what you are asking, grabs the right slice, and answers with citations, entirely in your browser. There is no model behind it. It is dumb in the one honest way that matters: it only repeats what the data actually says.
- No backend, no API keys, no bill. The Python builds a pile of JSON, a React app reads it, and the whole site is static. It costs me zero dollars a month to run, which is the correct price for a side project.
The part where it looked like every other AI side project
Let me be honest about the embarrassing stretch. The first UI I shipped was fine. Clean. Centred. Four identical cards. The kind of thing that quietly announces "a language model made this on a Tuesday."
I looked at it and thought, this is boring, and minimal is not supposed to mean boring. Minimal is supposed to mean expensive. So I threw it out and gave it an actual opinion. Editorial. Serif headlines in Fraunces, a clay accent instead of the regulation startup purple, warm off-white paper, hairline rules, little index numbers like a research journal. The signature move is a live knowledge graph that shows a real problem branching into its attempts and breakthroughs, because the product is the graph. You may as well lead with the good part.
It took a few tries. The lesson, again: the engine was done in days. Making it not look generic took embarrassingly longer.
What it can't do yet
- It only knows computer science right now. The engine does not care about the domain, widening it is basically one filter, but I had to start somewhere.
- "Problems" are topics plus clustering, which is coarser than reading every paper end to end. The full LLM pass is built and wired. It is just switched off until I feel like paying for it.
- Some citation counts look low because OpenAlex splits them across duplicate records. "Attention Is All You Need" shows a number that would make Vaswani quietly put down his coffee. Not my bug, but I am not hiding it either.
So
I set out to answer one question, "how did this problem evolve," without drowning in PDFs. Now I can. You walk in through a problem, watch it grow decade by decade, see what won and what is still open, and ask it questions in plain English, and nothing in it is allowed to lie to you. Which already puts it ahead of most of the internet.
That feels like the right shape for knowledge. Less library, more map.
It is at evolve-snowy.vercel.app, the code is on GitHub, and if you want to argue about whether "topic" and "problem" are the same word (they are not), my inbox is open.